
 [Operating Systems] File Systems
[Operating Systems] File Systems
파일은 Secondary storage에 저장하는 논리적인 최소 단위이다. 즉 사용자 입장에서 보면 이름 붙여진 sequence of bytes이고, 파일 시스템 입장에선 disk block의 콜렉션이다. 파일 시스템이 하는 일은 사용자 측면에서 파일을 바라보고 이름으로 접근하면 그것을 디스크 블락으로 나타내 주는 것이다. 파일 시스템은 disk와 같은 secondary storage에 있으며 데이터를 저장하고 가져오는 것을 쉽게 해준다. 파일은 ADT이며 그것에 대응하는 오퍼레이션들을 가진다. 디렉토리는 특수한 파일로써 파일들을 포함하는데 디렉토리에 속하는 파일을 접근할때 search해야 하는 문제가 발생하므로 OS는 Open File table을 관리하고 파일을 오픈할 경우 그 table의 인덱스를 ..
 [Operating Systems] Virtual Memory
[Operating Systems] Virtual Memory
Virtual Memory(가상 메모리) 기법은 사용자의 logical memory와 physical memory를 분리하기 위한 기술이다. 이를 이용하여 Logical address space가 physical address space보다 커지는 것을 가능하도록 한다. 이러한 virtual memory는 Demand paging이라는 기법을 이용하여 구현된다. Demand paging은 실제로 필요한 page만 메모리로 가져오는 것이다. 앞에서 언급했던 paging 기법에서는 프로세스의 메모리 공간을 다 할당해야 했기 때문에 사용되지 않는 부분까지 가져오는 불합리성이 있었는데 여기에서는 그 단점을 없앤다. 이것은 page table에 추가 엔트리를 부여하여 구현된다. valid bit라는 것을 두고 실..
 [Operating Systems] Memory Management
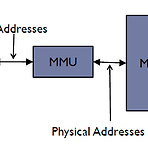
[Operating Systems] Memory Management
일단 메모리 관리의 필요성은 멀티프로세싱과 함께 출발한다. 멀티 프로세싱으로 인해 여러개의 메모리 공간을 필요로 하기 때문에 적절한 메모리 관리가 필요해진다. 우선 프로세스에게는 메모리가 여러 프로세스에 의해 공유되고 있다는 사실이 드러나서는 안되는 투명성(transparency)을 가져야 한다. 이것은 relocation을 이용해 각 프로세스마다 저장된 위치를 접근할 수 있도록 한다. 일반적으로 이 리로케이션은 실행 시간에 이루어지며, 하드웨어 서포트가 필요하다. 즉 MMU(Memory Management Unit)라는 하드웨어 모듈에 의해 프로그램이 바라보는 논리적 주소(Logical Address, Virtual Address)가 실제 하드웨어에 있는 물리적 주소(Physical Address)로 ..
스케쥴링은 멀티프로세싱 환경에서 다음에 실행될 프로세스가 무엇인지 결정하는 알고리즘이다. CPU 사용률, 스루풋, Turnaround time(특정 프로세스를 실행하는 시간), Waiting time(프로세스가 ready queue에서 대기하는 시간), Response Time(요청시간과 처리시간의 차이) 등의 기준에 따라서 스케쥴링의 성능을 판단하게 된다. 스케쥴링의 목적이라 함은 CPU사용률과 스루풋을 최대화 하면서 turnaround time, waiting time, response time을 최소화 하는 것이다. 스케쥴링 알고리즘의 종류로는 FCFS(First come First served), SJF(shortest job first), RR(round-robin), Priority based..
 [Operating Systems] Deadlock
[Operating Systems] Deadlock
동기화의 정의를 다시 되새겨 보면 동시에 실행되는 여러 프로세스가적절한 순서로 실행하는 것을 보장하고 레이스 컨디션이 생기지 않도록 하는 것이다. 동기화 기법에는 피터슨 같은 소프트웨어 기법, Testandset 같은 것을 사용하는 하드웨어 기법 등이 있다. 자, 다시 동기화의 전통적인 문제로 되돌아 가보자. 우선 첫째로 Bounded Buffer 문제이다. 이 문제는 버퍼의 크기가 한정되어 있고 그것을 접근할 때 버퍼가 오버플로 나지 않도록 하는 방법이다. 이것은 버퍼에 접근하는 부분 앞에 세마포어와 같은 동기화 메커니즘을 이용하고 버퍼의 크기 만큼 자원이 획득 가능하도록 하면 된다. Readers and Writers Problem도 마찬가지로 동기화 메커니즘을 사용해 해결 가능하다. 하지만 세번째 ..
프로세스에 이어서 스레드이다. 프로세스에서 다룰 때는 프로세스가 실행의 기본 단위라고 배웠지만 실제로는 그렇지 않다. 실제로는 프로세스는 할당의 기본 단위이고 스레드는 실행과 스케쥴링의 기본단위라고 보면 된다. 스레드의 정의는 스스로의 실행 컨텍스트와, 레지스터, 스택을 가지고 실행하는 인스트럭션의 시퀀스 이다. 즉 프로세스는 전체 프로그램과 실행 컨텍스트의 함으로 보면 되고 스레드는 프로그램의 부분과 실행 컨텍스트의 부분집합으로 보면 된다. 즉 같은 프로세스 내의 스레드는 코드, 데이터, 파일은 공유하며 각각 고유의 스택과 레지스터를 가지게 된다. 프로세스와 스레드의 차이는 위에서 언급한 단위의 차이도 있고, 커뮤니케이션 오버헤드에서도 차이가 난다. 프로세스같은 경우에는 프로세스간 커뮤니케이션(Inte..
컴퓨터 시스템은 크게 네가지 구조(Structure)으로 나뉜다. User, Hardware, Application Programs, Operating System 이다. 이 중 OS는 User와 Application이 Hardware를 사용하는 것을 통제하고 조정하는 역할을 한다. 하드웨어 사용을 통제없이 아무 어플리케이션에서나, 혹은 유저가 사용할 수 있도록 하면 시스템의 안전성이 매우 떨어질 것이므로 그것을 중재해주는 OS가 필요하다. 실제로 예전 MS-DOS에서는 아무 레이어에서나 하드웨어 접근이 가능했으므로 소위 '뻑'이라는 현상이 잦았다. 또한 다른 입장에서 Computer System Organization은 CPU와 기타 하드웨어들이 메모리를 접근하는 형태로 이루어진다. 각각의 하드웨어와 ..
- Total
- Today
- Yesterday
- 대학원
- Algorithms
- 데이터 사이언스
- 리눅스
- 자료구조
- 리버스엔지니어링
- Discrete Mathematics
- 개발
- 이산수학
- android
- 자바
- Reverse Engineering
- java
- 카타르
- 머신러닝
- 카타르 음주
- reversing
- 통계학습
- Data Structure
- 데이터 과학
- 안드로이드
- 리버싱
- 운영체제
- 기계학습
- 알고리즘
- Data Science
- operating systems
- linux
- Machine Learning
- statistical learning
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | |||
| 5 | 6 | 7 | 8 | 9 | 10 | 11 |
| 12 | 13 | 14 | 15 | 16 | 17 | 18 |
| 19 | 20 | 21 | 22 | 23 | 24 | 25 |
| 26 | 27 | 28 | 29 | 30 |